Computer vision engages with a significant challenge: bridging the gap with the exceptional human visual system. The hurdles lie in translating human knowledge for machines and meeting computational demands. Advances in artificial intelligence and innovations in deep learning and neural networks are used for computer vision applications to enable machines to interpret, understand, and derive meaning from visual data, closely mimicking human cognitive processes. Computer vision process involves image processing, feature extraction, image classification, object detection and image segmentation.

Image Processing: The Science Behind Sharper Images
Image processing in computer vision aims to enhance image data by minimizing distortions and highlighting relevant features, preparing the image for subsequent processing and analysis tasks. It entails applying a range of techniques, including resizing, smoothing, sharpening, contrasting, and other manipulations, to enhance the quality of an image. It is fundamental for extracting meaningful information crucial for tasks like object detection, image segmentation, and pattern recognition. A Convolutional Neural Network (CNN) is a deep learning algorithm of computer vision designed for image processing. Using convolutional layers, it extracts features like edges and shapes.

Feature Extraction: Separating the Wheat from the Chaff in Images
Feature extraction in computer vision involves converting raw data into a usable format for model training by extracting relevant features, such as the shape, texture, color, edges, or corners of an object within an image. Edge detection identifies boundaries between regions in an image, capturing the shape and structure of objects for further analysis. In addition, the texture analysis process identifies recurring patterns in an image, enabling the detection of textures and differentiation between various materials or surfaces of objects. Feature extraction serves as a critical preprocessing step in machine learning, enabling algorithms to discern meaningful patterns and relationships within data, leading to robust and insightful model outcomes across diverse domains.
CNN is a widely used computer vision algorithm for feature extraction to learn directly from raw data. It undergoes training on an extensive dataset of labeled images, learning to discern the crucial patterns associated with various image classes. Notably, it has been employed in categorization of tumour disease from MRI images. In this process, original images are input into the convolution network, and feature extraction techniques are applied to study brain MRI images.

Image Classification: How AI Decides What’s in an Image
Image classification in computer vision involves the categorization of images into different groups based on certain criteria or features. It classifies images into predefined categories, facilitating efficient organization and retrieval. This involves analyzing images at the pixel level to determine the most fitting label for the entire image. In computer vision, analyzing individual pixels is crucial before labeling the entire image. Image classification treats the image as a matrix array based on its resolution, grouping digital image pixels into classes. The image is transformed into key attributes, ensuring reliance on multiple classifiers. Image classification has two main categories: unsupervised and supervised techniques.
Unsupervised Classification: An automated method using machine learning algorithms to analyze and cluster unlabeled datasets, identifying hidden patterns through pattern recognition and image clustering.
Supervised Classification: It uses previously labeled reference samples (ground truth) for training. It visually selects training data samples within the image and allocates them to pre-chosen categories.
YOLO, or You Only Look Once algorithm efficiently combines image classification and localization in a single neural network pass. By dividing the image into a grid and predicting bounding boxes or rectangular frames for objects in one go, YOLO achieves exceptional speed, checking 45 frames per second. Image classification applications are used in many areas, such as medical imaging, traffic control systems, brake light detection, etc.
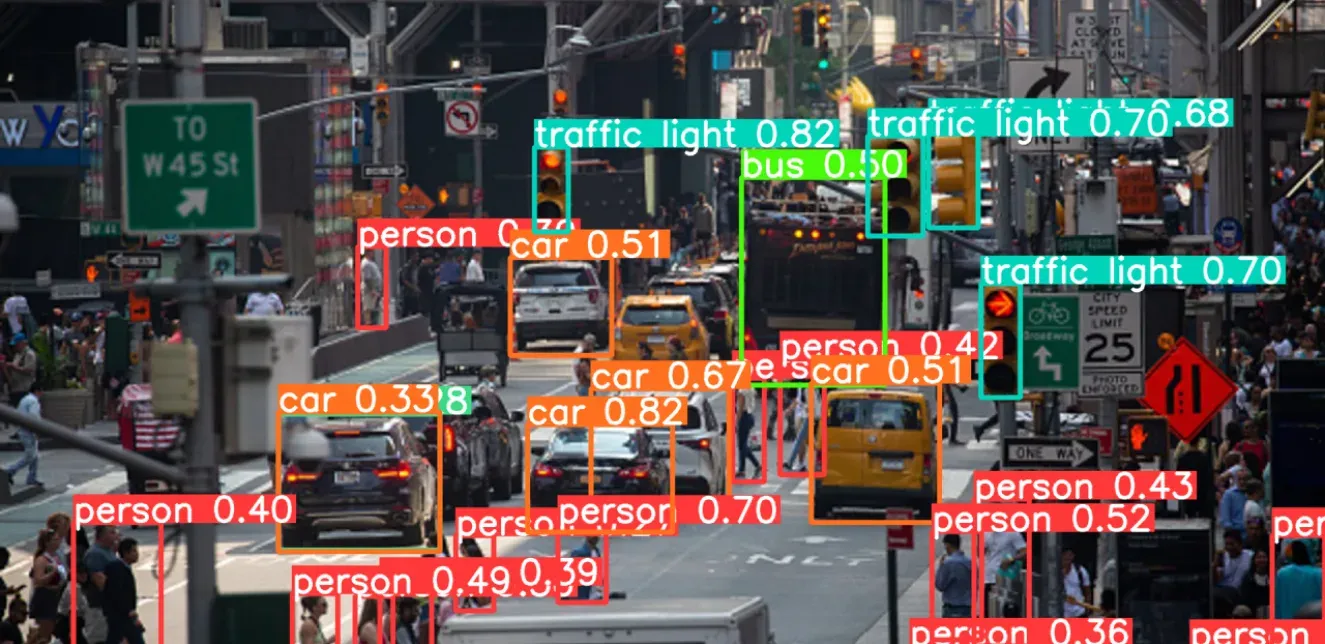
Object Detection: Telling Apples from Oranges
Object detection in computer vision involves identifying and locating specific objects within an image or video frame. It involves drawing bounding boxes around detected objects which allows us to locate and track their presence and movement within that environment. Object detection is typically divided into two stages: single-stage object detection and two-stage object detection.
Single-stage object detection involves a single pass through the neural network, predicting all bounding boxes in a single operation. The YOLO model, a single-stage object detection algorithm, performs simultaneous predictions of object bounding boxes and class probabilities across the entire image in a single forward pass.
Two-stage object detection involves the use of two models: the first model identifies regions containing objects, while the second model classifies and refines the localization of the detected objects. RCNN is a two-stage object detection model that is used to address variations in position and shape of objects in images. It efficiently identifies 2000 important regions, or “region proposals,” for further analysis. These chosen regions are processed through a CNN, serving as a feature extractor to predict the presence and precise location of objects, refining the bounding box for a more accurate fit.

Image Segmentation: Reading Between the Lines of Image Structures
Image segmentation in computer vision is the process of partitioning an image into meaningful segments based on pixel characteristics to identify various objects, regions, or structures to enhance clarity and analyzability. It uses two main approaches: similarity, where segments depend on similar pixel characteristics, and discontinuity, where segments result from changes in pixel intensity values. Segmentation methods include:
Instance Segmentation: Detects and segments each individual object in an image, outlining its boundaries.
Semantic Segmentation: Labels each pixel in an image with a class label to densely assign labels to generate a segmentation map.
Panoptic Segmentation: Combines semantic and instance segmentation, labeling each pixel with a class label and identifying individual object instances in an image.
CNNs are important deep learning models of computer vision that helps in image segmentation. Object detection algorithms first identify object locations using a region proposal network (RPN), generating candidate bounding boxes. After classification, in the segmentation stage, CNNs extract features from the region of interest (ROI) defined by the bounding box, feeding it into a fully convolutional network (FCN) for instance segmentation. The FCN outputs a binary mask identifying pixels belonging to the object of interest.
For example, image segmentation is useful for studying roads. It helps identify drivable areas, shows where there’s free space, and points out road curves, giving a closer look at the road environment. Understanding that a particular point on the camera indicates a road is not enough for recognizing free space and road curves. To address this, the information from the segmentation mask is combined with Bird Eye View (BEV) conversion. This process transforms the data into a useful 2D format. The integration of Panoptic Segmentation with Bird-Eye-View Networks proves practical for identifying free space and road curves.

In conclusion, understanding the intricacies of computer vision unveils the transformative power of computer vision AI in many industries. From precise image recognition to advanced object detection, computer vision showcases the incredible potential of implementing artificial intelligence in operations.
Transform your business operations with advanced computer vision AI services from Random Walk. Our computer vision solutions, like real-time safety monitoring and quality control, bring precision to your operations. Learn more about the future of AI in operations and integrate artificial intelligence in your organization with our tailored AI integration services.