What is Object Detection?
Object detection is a process in computer vision that involves identifying specific objects and their locations within digital images or video frames. This process involves two key steps: detecting the object or localization and then classifying it into one of the predefined categories (such as humans, animals, vehicles, etc.).
Objects in a picture are identified by drawing a rectangular box or bounding box around it to locate exactly where the object is. The box is defined by its top-left and bottom-right corner coordinates, with (0,0) typically set as the image's top-left corner. Image classification involves passing the contents of each bounding box through a trained neural network or other machine learning (ML) model for recognizing objects. This model assigns probabilities to predefined categories, indicating the likelihood of the object belonging to each category. The category with the highest probability is then selected as the classification for the object in the bounding box.
In object detection, anchor boxes are pre-defined boxes of a variety of shapes and sizes that are placed at different locations across an image. These anchor boxes serve as reference templates for detecting objects of various sizes and aspect ratios. During training, the model predicts adjustments to these anchor boxes to better fit the objects in the image. Anchor boxes help the model localize and classify objects by providing prior knowledge about where objects are likely to be found and in what sizes and shapes they might appear.

Image a) indicates bounding boxes that outlines the actual regions within the image that encompass the objects of interest
Image b) indicates anchor boxes that serve as reference bounding boxes utilized for predicting object locations and shapes
Object Detection Explained: The Mechanisms Involved
Object detection can be performed using either traditional machine learning (ML) methods or deep learning networks. Traditional object detection models like HOG, SIFT, SURF combined with SVM, Haar Cascades, and template matching suffer from limitations in representational power, struggling with variability in object appearance and requiring manual feature engineering. These methods often lack generalization to unseen object classes and can be computationally inefficient, hindering real-time processing. While effective in some scenarios, they are overshadowed by modern deep learning approaches, which offer greater flexibility, scalability, and robustness. Meanwhile, deep learning networks like convolutional neural networks (CNN) and region-based convolutional neural networks (RCNN) offer greater accuracy and versatility.
In deep learning based object detection, neural networks analyze images or video frames to identify patterns learned from extensive datasets. Using algorithms like Region Proposal Networks (RPNs), the system suggests potential regions of interest (ROI) where objects may be found and is then classified and assigned a bounding box. The system refines these results based on confidence scores, indicating the certainty in its predictions before presenting the detected objects as output.
Object detection is categorized into two: Single-stage object detection and two-stage object detection.

Single-stage networks like YOLO utilize anchor boxes instead of RoI extraction process to generate predictions for regions across the entire image, which are then decoded to generate final bounding boxes for objects. While single-stage networks are faster than two-stage networks, they may not achieve the same accuracy, particularly for recognizing small objects.
In two-stage networks like R-CNN and its variants, the first stage identifies RoI and the second stage then classifies the objects within these proposals. While two-stage networks can achieve highly accurate object detection, they tend to be slower compared to single-stage networks. For example, in a comparative study evaluating the performance and efficiency of single-stage and two-stage object detectors, findings demonstrated that Faster R-CNN achieves a mean average precision (mAP) score of 0.7837 with an average processing time of approximately 7.74 seconds per image. In contrast, SSD achieves a mAP score of 0.69 in approximately 0.56 seconds.
The Top Object Detection Algorithms and How They Work
Deep learning has transformed computer vision and object detection algorithms, driving impressive advancements in the field. Here are some of the popular traditional and deep learning object detection models.
Histogram of Oriented Gradients (HOG)
Histogram of Oriented Gradients (HOG) extracts essential image information while filtering out unnecessary details. By analyzing gradient (changes in pixel intensity) directions, it highlights significant image areas. It divides the image into sections, computes gradients, and creates histograms to represent image features. These histograms are combined to form a concise feature vector describing the image. However, its drawbacks include time-consuming pixel computations for complex images and limitations in detecting objects within confined spaces.

In this image segment, HOG model first computes gradients in small 8×8 cells and checks the edges in different directions, resulting in 64 vectors. These vectors are then split into nine categories based on their direction. The model combines them from overlapping squares to form bigger areas, fine tunes the area, and combine them to obtain an overall HOG feature.
HOG stands out by capturing fine details, making it particularly effective for applications requiring high precision on smaller scales—such as extracting facial features from a single image. It excels at recognizing essential outlines in larger objects, like cars, and operates efficiently on standard machines. However, a notable drawback is the increasing size of its descriptor vector, which results in longer feature extraction and training times compared to deep learning algorithms.
Chest X-ray images are crucial for diagnosing COVID-19. A computer vision approach was proposed using a fusion of features extracted from X-ray images by HOG and CNN. The fusion, along with CNN training, achieves a testing accuracy of 99.49%, specificity of 95.7%, and sensitivity of 93.65%. The method involves converting images to grayscale, extracting features using HOG and CNN, and fusing them for training the classification model. Notably, the fusion approach of HOG and CNN features outperforms individual methods, with CNN providing the best results as a binary classifier for chest X-ray datasets. While the number of features extracted by each technique alone may not be sufficient for accurate COVID-19 identification, combining both methods yields a larger feature set, enhancing identification accuracy.
Region-based Convolutional Neural Networks (RCNN)
R-CNNs represent a significant improvement in object detection. These models select proposed regions from an image, often using anchor boxes, and then label these regions with categories and bounding boxes. They use selective search algorithms to divide the image into nearly two thousand region sections, identifying potential object locations by hierarchically grouping similar pixels into regions. The features are then extracted using pre-trained convolutional neural networks (CNNs). Finally, predictions are made for each task using classification and regression models to label the bounding boxes and accurately predict the quantity of input data respectively.

The R-CNN algorithm advances past its predecessors by autonomously detecting key features without human intervention. It’s computationally efficient, utilizing pooling to reduce spatial dimensions by segmenting feature maps into smaller areas, thus preserving essential information. Parameter sharing further enhances its capability, applying the same set of weights across different spatial locations to detect similar patterns across input data. R-CNN is a practical choice for smaller projects with limited image datasets, effectively handling smaller data volumes and large objects by randomly selecting regions for CNN processing. However, its fixed region sizes may cause image distortion, and performing convolutions on every regional proposal can lead to inefficiency.
Faster-RCNN
The introduction of Fast R-CNN addressed some shortcomings of R-CNN by passing the entire image through a pre-trained CNN and employing RoI pooling for improved speed. Faster R-CNN enhances performance by replacing the selective search algorithm with a more efficient region proposal network (RPN), which computes image regions at various scales, drastically reducing computation time. The RPN utilizes anchor boxes to predict binary classes and generate bounding boxes, followed by non-maximum suppression to remove overlaps before proceeding with RoI computation and subsequent processing.

YOLO (You Only Look Once)
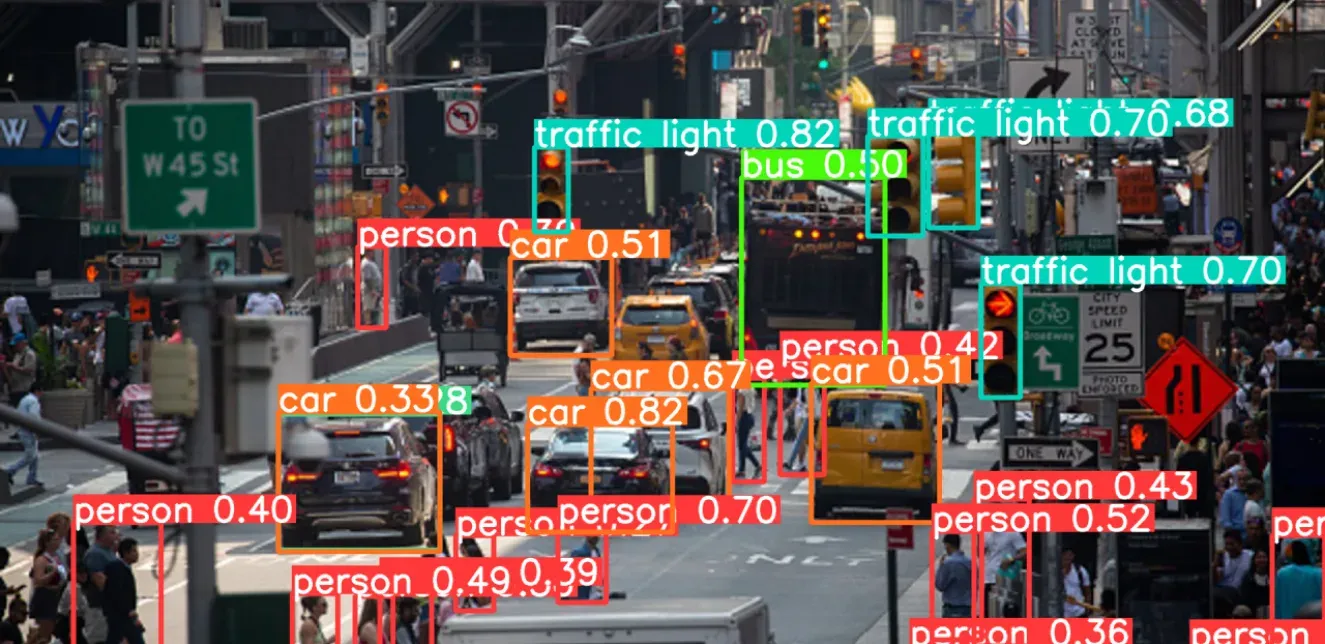
YOLO is a real-time object detection algorithm known for its high accuracy and speed of processing. The model divides the input image into small grids and makes predictions based on each grid. It creates bounding boxes around objects by considering the central points of each grid. Finally, it uses a method called intersection over union (IOU) that measures the overlap between the predicted bounding box and the ground truth bounding box, ie., the true position of the object in the image. This method identifies the best bounding boxes for the objects and helps YOLO work fast and effectively in detecting objects in images.

This image shows the YOLO algorithm analyzing digital images of complex fluid dynamics, specifically focusing on tracking moving droplets in multi-core emulsions and soft flowing crystals.
YOLO has remarkable speed in processing images, at a speed of 45 frames per second. It excels in comprehending generalized object representations, enabling it to perform well on both real-world images after training. It faces challenges when dealing with small objects clustered together, such as a flock of tiny birds, and struggles to generalize objects with new or unusual aspect ratios or configurations.
A study was conducted on detecting cars using SVM (Support Vector Machine) and YOLO. It compares the accuracy and performance of these methods. SVM is a supervised machine learning algorithm commonly used for image classification tasks. The initial step in preparing images for the SVM classifier involves extracting HOG features, which aims to identify images as groups of local histograms. The YOLO network was pre-trained to recognize 20 classes including cars. The SVM-based technique exhibited a significant number of false positives. SVM incorrectly identified road signs, trees, and pedestrians as vehicles in some frames. Implementing pre-road or line detection that identifies and delineates the boundaries or markings of a road or lane allows to send smaller and more relevant segments to YOLO, mitigating distortions and potentially improving results. The results showed that YOLO gave more accurate results and performed faster.

Single Shot Detector (SSD)
SSD is a faster alternative to methods like Faster R-CNN for detecting objects in real-time. While Faster R-CNN is accurate, it's slow, processing about 7 frames per second. SSD improves this speed by almost five times by using multi-scale features and default boxes instead. The first step is feature extraction, where important features like edges, textures, shapes, or other patterns are picked out using fully convolutional layers. Then, in the next stage called "detecting heads," another set of CNNs is used to create bounding maps for these features. Finally, the results go through non-maximum suppression layers to get rid of duplicate bounding boxes and reduce errors.
SSD has ability to make numerous predictions and has an excellent control over location, scale, and aspect, particularly beneficial for low-resolution images. When dealing with large datasets of degraded quality images or older images with low resolution, SSD excels due to its robust control over these factors, even though it may require a substantial number of images for training.
Incorporating object detection capabilities into computer vision models enhances their ability to accurately identify and analyze visual data, benefiting industries. These advancements promise increased efficiency, safety, and decision-making capabilities across various sectors, propelling towards a future of seamless interaction between intelligent systems and their surroundings.
Transform your business with leading computer vision AI Services from Random Walk. Visit our website to know more about our AI integration services that can revolutionize the way you harness artificial intelligence for your operations.