In an interview with Joe Rogan, Elon Musk described his “Not a Flamethrower” as more of a quirky novelty than a real flamethrower, calling it a roofing torch with an air rifle cover. He also explained the reasoning behind its name—avoiding shipping restrictions and simplifying customs procedures in countries where flamethrowers are prohibited.
When the OpenAI GPT-3.5 Turbo model was asked, "What are Elon Musk’s views on flamethrowers?" it captured this insight effortlessly, showcasing the potential of AI to extract meaningful information from complex datasets like interview transcripts.
Now imagine using similar AI capabilities to query complex datasets like interview transcripts. What if you could upload a PDF, ask nuanced questions, and instantly uncover relevant insights—just as GPT models interpret context? This blog explores how to leverage AI and natural language processing (NLP) to create a system capable of analyzing and querying a PDF document—such as Elon Musk's interview with Joe Rogan transcript—with remarkable accuracy.
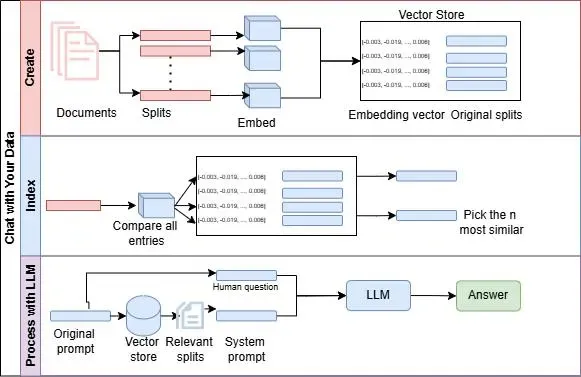
Overview of the Workflow
The system performs the following:
- ● Load and preprocess a PDF document.
- ● Split the content into manageable chunks for analysis.
- ● Embed the document into a vector database for efficient retrieval.
- ● Utilize a language model to retrieve and answer queries.
Let’s dive into the technical details.
Step 1: Loading the PDF Document
LangChain supports a wide variety of document types as input through different document loaders. Text based documents like plain text files (.txt), markdown files (.md), html, json and csv files, office documents like .docx, .pptx, .xlsx and PDF files, web and online content - web pages, Notion pages, Confluence and slack messages. Proprietary data sources like python files, cloud storage, APIs and emails can also be loaded. Unstructured data sources like images with OCR and ZIP archives can also be loaded. This wide range of supported documents makes LangChain flexible and versatile for various data ingestion workflows.
To begin, we load the PDF file using the PyPDFLoader from LangChain:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("Elon_Musk.pdf")
pages = loader.load()This step extracts the pages of the PDF into manageable data structures for processing.
Step 2: Splitting the Document into Chunks
Large documents need to be divided into smaller chunks for effective processing and meaningful responses. Using the RecursiveCharacterTextSplitter, the content is split based on logical separators such as paragraphs or sentences. There are other text splitters but Recursive Character is the most efficient of them for this use case. When using LangChain to interact with PDF data, splitting documents into smaller chunks is essential for models to effectively analyze and retrieve relevant information without exceeding token limits. LLMs like OpenAI’s GPT have a maximum context window of around 4,000 to 8,000 tokens for most models, restricting how much text they can analyze in a single query.
Additionally, chunking improves the accuracy and relevance of query responses. Targeted retrieval reduces noise from unrelated sections and enhances the precision of the response. Moreover, chunking allows the use of vector databases for semantic search, enabling faster and more contextually accurate matches. Overall, document chunking optimizes both performance and user experience when building conversational AI systems with LangChain.
from langchain.text_splitter import RecursiveCharacterTextSplitter
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500,
chunk_overlap=150,
separators=["\n\n", "\n", "(?<=\. )", " ", ""]
)
splits = r_splitter.split_documents(pages)This approach ensures overlapping chunks, preserving context between sections.
Step 3: Embedding Content with OpenAI
Embeddings transform text into numerical representations that capture semantic meaning. These are stored in a vector database for similarity searches. The OpenAIEmbeddings class from LangChain is used to convert document chunks into high-dimensional vector representations. These embeddings capture the contextual meaning of the text, enabling the system to understand and compare content beyond simple keyword matching. This process is essential for building applications like intelligent search engines, chatbots, or recommendation systems where understanding the intent and context of queries is critical.
The embedded vectors are stored in a Chroma vector database, specified by the persist_directory = 'docs/chroma/'. Chroma is optimized for handling and querying vectorized data, allowing for fast and accurate similarity searches. By converting documents (split into smaller chunks) into embeddings and storing them in Chroma, the system can quickly retrieve the most relevant pieces of information in response to user queries. This setup not only accelerates data retrieval but also enhances the quality of results by focusing on semantic relevance rather than exact text matches, making it a powerful foundation for AI-driven search and analysis applications.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embedding = OpenAIEmbeddings()
persist_directory = 'docs/chroma/'
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory
)This setup creates a robust foundation for querying the document.
Step 4: Querying with Natural Language
Querying with natural language using LangChain simplifies the process of extracting relevant information from large datasets or documents.To retrieve information, the system uses a self-querying retriever that interacts with the vector database using natural language prompts. OpenAI language model (gpt-3.5-turbo-instruct) is used to interpret and process user queries. This model, integrated through the SelfQueryRetriever, allows users to ask questions in plain, conversational language without needing to know complex query syntax or database structures. The model intelligently understands the query context and searches for semantically relevant information within the vector database (vectordb), which contains embedded document data.
To enhance search accuracy, metadata is incorporated through AttributeInfo, specifying details like the source document and page number. This metadata-aware retrieval allows the model to not only locate content that matches the query but also provide contextual details about where the information is sourced. For example, when asked, _"What are Elon Musk's views on flamethrowers?"_, the retriever interprets the intent and pulls the most relevant excerpts from the interview document. This seamless natural language querying capability bridges the gap between human language and machine understanding, making data interaction more intuitive and efficient.
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
llm = OpenAI(model='gpt-3.5-turbo-instruct', temperature=0)
metadata_field_info = [
AttributeInfo(
name="source",
description="The interview is between Joe Rogan and Elon Musk from,'Elon_Musk.pdf'",
type="string",
),
AttributeInfo(
name="page",
description="The page from the interview",
type="integer",
),
]
retriever = SelfQueryRetriever.from_llm(llm, vectordb, "Interview with Joe Rogan and Elon Musk", metadata_field_info, verbose=True)
question = "What are Elon Musk's views on flamethrowers?"
docs = retriever.get_relevant_documents(question)This method dynamically interprets and retrieves the most relevant document segments.
Step 5: Generating Answers with an LLM
Generating answers from an LLM using LangChain's RetrievalQA chain allows for a seamless integration of data retrieval and intelligent response generation. The RetrievalQA chain combines the power of a language model (llm) with a vector database retriever (vectordb). This approach significantly improves the quality of responses by grounding the language model’s answers in factual data retrieved from the provided document set. The RetrievalQA chain ensures that the generated answers are not purely based on the model’s general knowledge but are directly tied to the source material. This minimizes hallucination (i.e., the generation of inaccurate or fabricated information) and enhances the reliability of the output.
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectordb.as_retriever())
result = qa_chain({"query": question})
print(result["result"])This ensures the answers are contextually accurate and user-friendly.
Key Benefits of a LangChain Conversation System
Efficient Information Retrieval
The use of vector databases enables quick and precise retrieval of relevant chunks of text. Large PDFs are automatically split into manageable chunks, improving search efficiency and ensuring that even massive documents can be searched quickly. This chunking allows for precise and relevant information retrieval without overwhelming the model or missing important context.
Natural Language Interaction
By leveraging OpenAI’s LLMs, the system can handle natural language queries, making it intuitive for non-technical users.
Custom Metadata Integration
The inclusion of metadata like source and page numbers enhances traceability and context in responses.
Customizable Workflows and Pipelines
LangChain supports modular and customizable workflows, allowing developers to tailor how PDFs are processed, indexed, and queried. This flexibility enables seamless integration into various applications like document search engines, chatbots, and data analysis tools.
This system exemplifies how AI can transform document analysis and querying. By combining document loaders, text chunking, embeddings, and LLM-powered retrieval, it unlocks a world of possibilities for extracting insights from complex datasets. By combining retrieval and generation in a single pipeline, this method provides users with accurate, well-structured, and contextually relevant answers, making it ideal for applications like document Q&A, customer support, and knowledge base search.
Code Base
All the code in this blog was used directly from the LangChain course on Deeplearning.ai titled - LangChain - Chat with Your Data.
References: