Reactive Programming is a paradigm that is gaining prominence in enterprise-level microservices. While it may not yet be a standard approach in every development workflow, its principles are essential for building efficient, scalable, and responsive applications. This blog explores the value of Reactive Programming, emphasizing the challenges it addresses and the solutions it offers. Rather than diving into the theoretical aspects of the paradigm, the focus will be on how Spring Boot simplifies the integration of reactive elements into modern applications.
To begin developing a structured understanding, it is important to go to the basics:
- ● A paradigm can be understood as a "style of programming" where various components interact within memory, as is typical in any programming approach.
- ● Many definitions of Reactive Programming describe it as “a declarative programming approach that deals with data streams in computers…” While the emphasis on data streams is important, the key takeaway is that Reactive Programming is inherently declarative. This means it prioritizes high-level abstractions, allowing developers to specify what should happen rather than focusing on the step-by-step implementation of how it should be done.
- ● The term "reactive" implies that components will interact as a reaction to other events. This approach contrasts with imperative or procedural paradigms, where explicit step-by-step instructions are defined. If one were to implement this paradigm manually, it would require adherence to declarative principles. The focus would be on reacting to external data emissions rather than controlling data streams directly.
At its core, Reactive Programming enables components to communicate through asynchronous data streams, providing an efficient way to handle changes and events. This makes it particularly valuable in scenarios where applications must manage large-scale, high-throughput, or real-time data interactions. While adopting reactive principles, frameworks such as Spring Boot provide powerful abstractions to simplify and streamline development efforts.
The following sections explore how Spring Boot simplifies the adoption of Reactive Programming, providing powerful abstractions that eliminate much of the complexity involved in manual implementation.
What are Asynchronous Data Streams?
To grasp the concept of asynchronous data streams, think of a river where water flows continuously. At any given moment, you can observe and react to changes in the flow—whether it's leaves, fish, or debris. The river never stops for observation; it keeps moving. If the goal is to catch fish, you must respond to their presence while ignoring other elements, allowing the river to flow uninterrupted. This analogy reflects the essence of asynchronous behavior. In an application built with this mindset, everything becomes asynchronous—whether this is advantageous or not will be explored further.
Another illustrative example involves a common scenario in operating systems: imagine a Windows PC that recently installed a faulty kernel-mode driver that needs to start at boot time (a nod to CrowdStrike is appropriate here). Windows has a failsafe mechanism—the infamous Blue Screen of Death (BSOD). This mechanism gracefully shuts down the PC to prevent corruption if any critical driver fails. Additionally, it logs details about what went wrong, aiding diagnostics.
The BSOD is more than just a frustrating screen; it serves as a safeguard, ensuring system integrity by preventing catastrophic failures. Microsoft engineers design this failsafe mechanism to react dynamically to critical failures, much like handling events in a reactive programming paradigm. The system’s ability to respond promptly and log valuable information mirrors the fundamental principles of reactive programming—observing, reacting, and maintaining system stability amidst unexpected events. You might describe it as:
function triggerBSOD() {
displayBlueScreen();
logErrors();
haltSystem();
}Now while implementing the startup process of the OS, you must initialise critical drivers, that are for various devices in your PC, as well as System drivers for Windows itself, you might implement in the following ways:
Reactive
on(event: DriverHealthCheck) {
if (event.driver.notHealthy() &&
event.driver.isRingZero()) {
triggerBSOD()
}
}Procedural
function checkForDriverException() {
if (kernel.driver.exception) {
triggerBSOD()
}
}Do you notice the key difference between these two approaches? One operates in a blocking manner, while the other is non-blocking. In the latter approach, the system must check drivers sequentially and continuously poll them to ensure security while the system is running. This process consumes valuable computing resources, as the hardware must repeatedly execute code responding to these system polls. Given that this occurs during startup—when the operating system is already under significant load—it can further slowdown performance.
In contrast, the former approach allows the system to operate normally while letting the driver emit an event in case of a crash. Upon receiving such an event, the OS can halt the system immediately.
While this is a high-level conceptualization and may not represent the exact implementation, it aligns with a reactive philosophy. To explore this concept further, search for “Windows Event Viewer” in the Windows search bar. This tool demonstrates how Windows tracks events, implying that reactive principles are employed within the system to some extent—and indeed must be.
Understanding Spring Boot’s Reactive Core
After this much preface, one might wonder, "Does this require extensive effort to implement?" Surprisingly, it’s not necessar. In Spring boot, which is the likely place you will be using Async operations, where a lot of services talk to each other, the implementation of the reactive paradigm is found in the Spring Reactor Core module. It provides a bunch of interfaces and methods that you can follow to get it working in no time. First, we need to understand a bit of architecture and procedure of how the whole flow goes in Reactor Module (along with terminologies).
import reactor.core.publisher.Flux;
public class ReactiveExample {
public static void main(String[] args) {
Flux<String> peopleEnteringRoom = Flux.just("John", "Alice", "Bob");
peopleEnteringRoom
.doOnNext(person -> System.out.println(person + " entered the room"))
.subscribe(person -> System.out.println("Lightbulb turns ON for " + person));
}
} In the given code, a Publisher is responsible for producing a sequence of data, or a stream, while a Subscriber consumes the emitted data. To receive data, a subscriber must first subscribe to a publisher, which can be either a Mono (emitting a single object) or a Flux (emitting multiple items).
Once subscribed, actions can be defined at various stages of data processing. For instance, the .doOnNext() method can be used to perform operations whenever new data is received—typically for side effects rather than modifying the data itself. In this example, peopleEnteringRoom acts as the Publisher, emitting a sequence of names. The .doOnNext() method logs each person's entry, while the subscribe() method defines the response to data consumption—such as turning on a lightbulb for every person entering the room.
Notice the declarative nature of the code—there is no explicit loop, yet every element is processed. This aligns perfectly with the reactive paradigm, emphasizing "what" should happen rather than "how" it should be done. This example represents a simplification, as Reactor provides numerous powerful features for handling complex data flows efficiently.
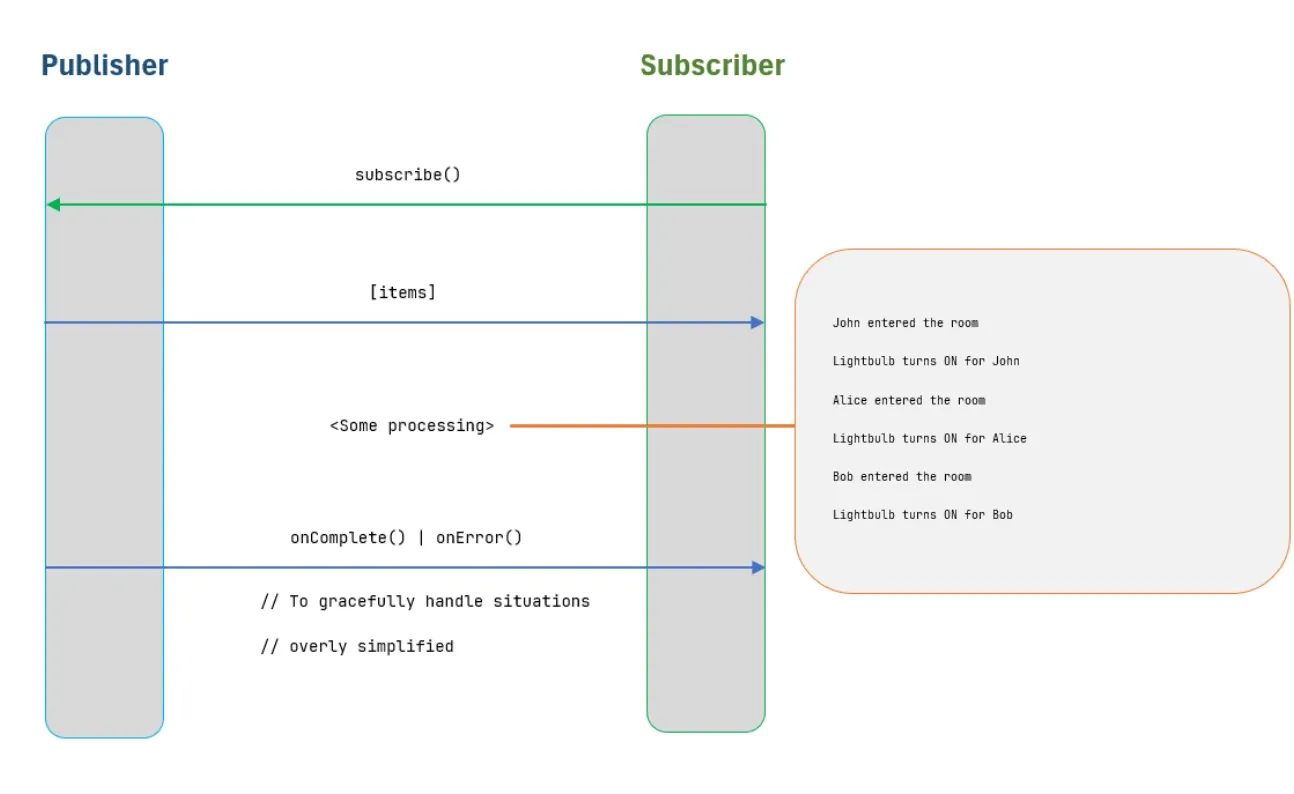
Let us now examine a practical scenario: suppose a service needs to make an API call to an external endpoint and store the results in a database. The challenge is that the system must not wait for the result. The steps are as follows:
- ● Start the request to the endpoint.
- ● Insert an IN_PROGRESS entry in the database as a placeholder.
- ● Return an immediate HTTP response indicating the IN_PROGRESS status.
- ● Once the request completes asynchronously, update the database with either READY or ERROR based on the result.
One approach Spring Boot provides is RestTemplate, an HTTP client for making requests. However, it operates synchronously, meaning it must be combined with mechanisms like CompletableFuture to achieve asynchronous behavior. The challenge here lies in thread management—handling thread allocation and deallocation carefully to avoid unintended procedural patterns.
That said, RestTemplate is now deprecated, and the recommended alternative is WebClient, which is part of Spring Reactor Core. If you're interested in exploring CompletableFuture in depth, we may cover it in a future blog post. For now, let’s focus on how Reactive Programming simplifies these challenges and enhances application responsiveness.
public Mono<MyClass> sendRequest(String endpoint, HttpHeaders headers, Map<String, String> body) {
return webClient
.post()
.uri(endpoint)
.headers(httpHeaders -> httpHeaders.addAll(headers))
.accept(MediaType.APPLICATION_JSON)
.bodyValue(body)
.exchangeToMono(response -> {
if (response.statusCode().is2xxSuccessful()) {
return Mono.empty();
} else {
return response.bodyToMono(ApiError.class)
.defaultIfEmpty(new ScraperError("Unknown error"))
.flatMap(error -> Mono.error(new RuntimeException(error.getError())));
}
});
} Let's dissect this now:
- ● This is a standard POST request, means data is sent, along with body, and headers (parameters of the function) (first 5 chained methods configure all this)
-
●
Since the request gives one output, the function will return Mono
which represent the object which will be saved eventually. exhangeToMono() makes the request.
- ● This function returns a Mono, which can either be empty or contain an instance of ApiError. The ApiError class is designed with fields that match the structure of the API response, allowing Jackson to handle the conversion from JSON to POJO based on these matching fields.
We can now invoke this with a wrapper function:
public Mono<MyClass> invoke(MyClass myClass) {
headers.set("X-API-KEY", API_KEY);
headers.setContentType(MediaType.APPLICATION_JSON);
return sendRequest(ENDPOINT, headers, requestBody)
.then(Mono.fromCallable(() -> updateObjectOnSuccess(myClass)))
.onErrorResume(e -> {
logger.error(e.getMessage());
return Mono.just(updateObjectOnError(myClass, e.getMessage()));
}); Let's dissect this as well:
- ● The input to this function is an instance of MyClass, which we expect to be updated based on the API call.
- ● Since sendRequest is now a Publisher, we can propagate another Mono upstream. In this case, we will handle errors and ensure that MyClass is updated using .onErrorResume(), eliminating any possibility of returning Mono.empty().
- ● This function is guaranteed to return an updated instance of MyClass, with its status either set to ERROR or READY. Initially, when the function is called, the status is IN PROGRESS, as we'll see in the following steps.
So, we are finally ready to subscribe to this publisher.
// after some code
invokeMyCall(myClass)
.subscribe(updatedMyClass -> {myRepo.save(updatedMyClass)});
myRepo.save(myClass); Based on what we've covered so far, we can infer the flow of the process. After the code we discussed, the invokeMethod will subscribe to the Publisher. Because of its asynchronous nature, it won't wait for the result, meaning the last line will be executed first. As a result, the status IN_PROGRESS has persisted to the database immediately.
Once the API call completes at some point in the future, another database call is made to update the status to either READY or ERROR, all while maintaining the asynchronous flow.
This approach allows you to achieve asynchronous behavior while keeping the code declarative and clean. The power of this framework is truly impressive.
Is asynchronous programming always the right choice? That ultimately depends on your system design and use case requirements. For certain scenarios, such as processing high volumes of concurrent requests or making non-blocking external API calls, asynchronous patterns are invaluable. However, the decision must align with both infrastructure design and operational goals. If you do need a scalable and declarative way to handle asynchronous operations, the Spring Reactor Core module provides a robust and efficient solution to meet those demands.