The AI race has long been dominated by proprietary giants like OpenAI, but a new contender is making waves—DeepSeek. With its latest open-source models, DeepSeek V3 and DeepThink R1, this Chinese AI company is challenging OpenAI’s dominance by offering competitive performance at a fraction of the cost.
DeepSeek’s Mixture of Experts (MoE) architecture, efficient GPU utilization, and strategic innovations have enabled it to deliver high-performance AI models with minimal computational expense. But how does it truly compare to OpenAI’s GPT-4o and GPT-o1? Let's break it down.
The Contenders: DeepSeek V3 vs. OpenAI GPT-4o
DeepSeek V3, also known as deepseek-chat, is an open-source language model that leverages the Mixture of Experts (MoE) architecture to deliver state-of-the-art performance. Trained on a cluster of 2,048 Nvidia H800 GPUs over two months, DeepSeek V3 achieved remarkable computational efficiency, costing approximately $5.6 million—a fraction of the cost of comparable models like GPT-4o.
With a context window of 128,000 tokens and the ability to generate up to 8,000 tokens, DeepSeek V3 is designed for high accuracy and efficiency. Its architecture incorporates advanced techniques like Multi-head Latent Attention (MLA) and an auxiliary-loss-free strategy for load balancing, ensuring optimal resource utilization and scalability.
On the other hand, OpenAI’s GPT-4o ("o" for "omni") is a proprietary, multilingual, and multimodal model that represents the pinnacle of OpenAI’s generative AI capabilities. Trained on approximately 25,000 Nvidia A100 GPUs over 90 to 100 days, GPT-4o boasts a context window of 128,000 tokens and can generate up to 16,384 tokens. While it offers superior output capacity, its training and operational costs are significantly higher than DeepSeek V3.
DeepThink R1 vs. OpenAI GPT-o1: The Battle of Reasoning Models
DeepSeek’s DeepThink R1 (deepseek-reasoner) is an open-source reasoning model that has quickly risen to prominence. According to the lmarena.ai Chatbot Arena LLM Leaderboard, DeepThink R1 is currently ranked 3rd, outperforming many of its competitors, including OpenAI’s GPT-o1.
DeepThink R1 is designed to excel in complex reasoning tasks, making it a strong contender in the AI space. Its affordability is another standout feature—96.35% cheaper than OpenAI’s GPT-o1. This cost advantage, combined with its open-source nature, makes DeepThink R1 an attractive option for developers and organizations looking to leverage advanced AI without breaking the bank.
Accessibility and Cost
When it comes to choosing an AI model, cost and accessibility are critical factors. Here’s a quick comparison of the input and output costs for these models:
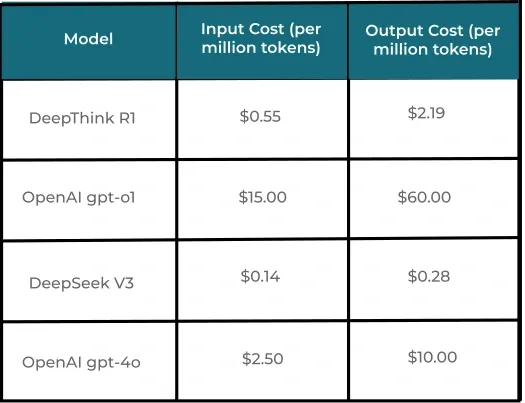
As evident from the table, DeepSeek V3 is 97.2% cheaper than GPT-4o, while DeepThink R1 is 96.35% cheaper than GPT-o1. This stark difference in cost makes DeepSeek’s models a compelling choice for users prioritizing affordability without compromising on performance.
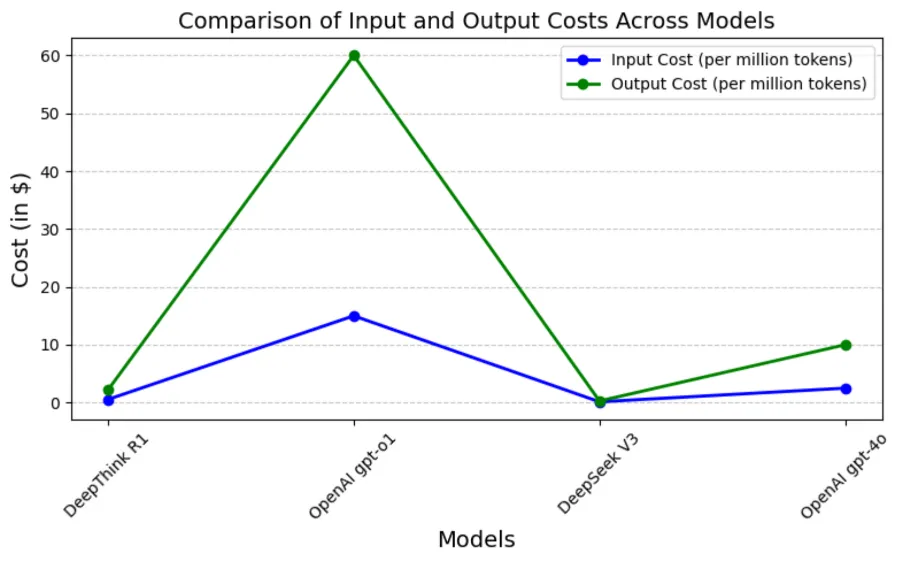
From the graph, OpenAI GPT-o1 has the highest token costs, while DeepSeek V3 remains the most affordable option for both input and output tokens.
Innovative Architectures: What Sets These Models Apart?
Mixture of Experts (MoE)
DeepSeek V3’s MoE architecture is a game-changer. It consists of multiple expert networks, each specializing in different aspects of the input data. A gating mechanism dynamically selects the most relevant experts for each token, ensuring sparse activation and optimal resource utilization. This approach not only enhances computational efficiency but also reduces training costs.
Multi-head Latent Attention (MLA)
Traditional attention mechanisms scale quadratically with sequence length, making them computationally expensive. DeepSeek V3’s MLA addresses this by operating on a compressed version of the input sequence, significantly reducing complexity and cost.
Auxiliary-Loss-Free Load Balancing
DeepSeek V3 employs a dynamic gating mechanism that inherently balances the load across experts, eliminating the need for auxiliary loss terms. This ensures efficient utilization of resources without compromising performance.
Multi-Token Prediction
During training, DeepSeek V3 predicts multiple future tokens in parallel, using multiple output heads. This innovative training objective enhances the model’s ability to generate coherent and contextually accurate outputs.
Final Thoughts: Is DeepSeek a True OpenAI Challenger?
DeepSeek V3 and DeepThink R1 present a serious alternative to OpenAI’s GPT models. With their cost efficiency, open-source nature, and high performance, they make AI more accessible to businesses, developers, and researchers worldwide. For those seeking a powerful yet affordable AI model, DeepSeek is a rising force to watch.