As data grows, enterprises face challenges in managing their knowledge systems. While Large Language Models (LLMs) like GPT-4 excel in understanding and generating text, they require substantial computational resources, often needing hundreds of gigabytes of memory and costly GPU hardware. This poses a significant barrier for many organizations, alongside concerns about data privacy and operational costs. As a result, many enterprises find it difficult to utilize the AI capabilities essential for staying competitive, as current LLMs are often technically and financially out of reach.
Understanding 1-bit LLMs: A Breakthrough Solution
A groundbreaking solution that addresses these challenges is 1-bit LLMs. Unlike traditional LLMs like GPT-4, LaMDA, PaLM, Gemini, LLaMA, and Claude, which typically require 32- or 16-bit weights to store parameter data, 1-bit LLMs use highly quantized representations—down to just three values (e.g., -1, 0, and 1). This compression reduces a model’s storage needs by around 97% and makes it possible to run sophisticated language models locally, using standard CPUs rather than specialized GPUs, thus eliminating the need for API calls to external servers.
To understand the significance of this achievement, consider that a traditional 7-billion parameter model typically requires approximately 26 gigabytes of storage space. The same model, when converted to a 1-bit LLM, requires only 0.815 gigabytes – a reduction of nearly 97%. Enterprises can run powerful AI applications without the need for a data center filled with GPUs, reducing the costs and risks associated with external dependencies, while enhancing data privacy.
The Technical Foundation: How 1-bit LLMs Work
The simplified computations that drive 1-bit LLMs allow them to operate efficiently on standard CPUs, even replacing GPUs in some cases. Typically, GPUs are favored for AI due to their ability to handle complex multiplications rapidly, a necessity in traditional neural network architectures. However, with 1-bit LLMs, the need for multiplications is eliminated. Here’s how it works:
Binary Neural Networks and Weight Quantization: Imagine storing only the essence of every book in a library rather than every detail. 1-bit LLMs use binary neural networks (BNNs) to retain only essential information, making the model lighter and faster. Like having a concise library where every book only keeps its key points, these models save space while ensuring critical information remains clear and accessible in high-detail “books.”
1-bit LLMs use two key approaches for efficient AI model compression:
Post-Training Quantization (PTQ) starts with a fully-trained model, compressing it by converting most parameters to 1-bit (either +1 or -1) while keeping critical ones at slightly higher precision. This method preserves model performance while significantly reducing size. It removes extra weight but reinforces key components to keep it stable.
Quantization-Aware Training (QAT) method trains the model from scratch with 1-bit parameters in mind. While this requires more effort, it optimizes the model for high efficiency from the start.
Eliminating Multiplications: Imagine counting a pile of stones by adding or removing them, rather than performing complex calculations. In a 1-bit LLM, weights are compressed to three values (e.g., -1, 0, and 1). This extreme quantization removes the need for multiplication altogether, allowing efficient calculations on CPUs by replacing complex operations with simple addition and subtraction. The model uses additions and subtractions for the -1 and 1 operations as addition and subtraction are much simpler and faster than multiplication, and it skips operations when a 0 is involved. This makes the whole process much faster and more efficient, saving on computation time and energy.
Enhanced Compatibility with CPUs: This quantization opens up new hardware possibilities, enabling CPUs to handle these models efficiently. The process minimizes energy consumption and computational demands, making 1-bit LLMs compatible with other hardware such as Application-Specific Integrated Circuits (ASICs).
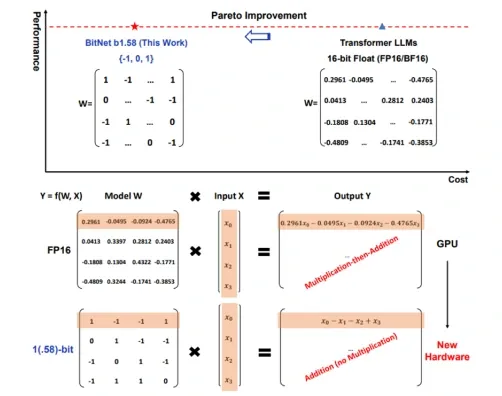
This figure shows that 1-bit LLMs, like BitNet b1.58, offer a balanced solution to lower the costs of running LLMs in terms of speed, efficiency, and energy use without sacrificing performance.
Real-world Impact: Solving Enterprise Challenges
The implementation of 1-bit LLMs addresses several critical enterprise challenges, transforming knowledge management capabilities along the way:
Eliminating Dependency on GPUs and External APIs: Traditional LLMs often depend on expensive third-party servers and APIs, raising concerns about data privacy, latency, and costs. Hosting 1-bit LLMs locally allows businesses to keep sensitive data secure and reduce operational expenses tied to cloud infrastructure. 1.58-bit LLMs like BitNet b1.58 are designed for edge and mobile devices, addressing their memory and computational limitations. With lower memory usage and energy consumption, they can be efficiently deployed on CPUs, enhancing performance. In a comparison of BitNet b1.58 to the FP16 LLaMA LLM, both trained on 100 billion tokens, BitNet b1.58 was 2.71 times faster and used 3.55 times less memory. For the larger 70B model, BitNet b1.58 was 4.1 times faster and saved a lot of energy. This efficiency enables it to operate effectively within the constraints of CPUs, which often have limited resources compared to GPUs.
Local hosting enables organizations to implement secure AI-powered knowledge management models and data visualization tools, like AI Fortune Cookie, for real-time document processing across structured and unstructured data. This setup enhances data security, reduces latency, and offers scalable document management without major hardware investments. Supporting document analysis, classification, and information extraction with natural language query capabilities, these models improve operational efficiency, decision-making, and data privacy while minimizing reliance on costly external APIs.
Processing Performance: Despite the effective compression, 1-bit LLMs achieve impressive processing speeds. They demonstrate speedups ranging from 1.37x to 5.07x on ARM CPUs and 2.37x to 6.17x on x86 systems. These models can process 5-7 tokens per second on standard CPU hardware. These models are optimized for speed, allowing it to process tasks more quickly on CPU-based systems. They are also able to handle various model sizes effectively means it can be tailored to fit different CPU capabilities, making it versatile for various applications.
Energy and Cost Efficiency: The energy efficiency gains of 1-bit LLMs are remarkable. Tests show a 55-70% reduction in energy consumption on ARM CPUs and 71-82% savings on x86 processors. This translates directly into lower operational costs and a reduced carbon footprint, helping organizations meet both financial and sustainability goals. This is important for CPUs in mobile and edge devices, as energy efficiency can extend battery life and reduce operational costs.
Looking Ahead: The Future of Enterprise AI
The development of 1-bit LLMs represents more than just a technical achievement – it marks a fundamental shift in how enterprises can approach AI implementation. By effectively reducing resource requirements while maintaining high performance levels, these models democratize access to advanced AI capabilities.
For enterprises, this means:
- ● Reduced initial investment requirements
- ● Lower ongoing operational costs
- ● Better control over data privacy and security
- ● Simplified deployment and maintenance procedures
- ● Increased accessibility of AI capabilities across departments
As the technology continues to mature, we can expect to see more organizations adopting these efficient models for their AI initiatives. This widespread adoption will likely drive further innovations in model efficiency and enterprise applications, creating a positive cycle of technological advancement and practical implementation.
To learn more about enterprise knowledge management models and solutions for effectively managing your organization across various departments, contact Random Walk AI for a personalized consultation with our experts. Visit our website to discover how our data visualization tool using generative AI, AI Fortune Cookie, can help you overcome your data management challenges and manage and visualize the data for optimizing your operations tailored to specific enterprise use cases.